
はじめに
対象読者・想定読者
- 楽譜が欲しいピアノ曲があるが、楽譜が売ってない(CDなどの音源はある)
- 楽曲解析したいピアノ曲があるが、1から耳コピはしんどい
- ソルフェージュ練習でピアノ曲を耳コピしたので答え合わせがしたい
この記事でわかること
- Piano Transcriptionとはどんなソフトなのか、何ができるのか
- Piano Transcriptionの使い方 基本と応用
使い方を把握するには英語とプログラミングの知識が必要になるソフトです。
しかし安心してください。
この記事では日本語とキャプチャを用いてわかりやすく使い方を解説します。
2023年3月21日現在、Piano Transcription内の音声処理モジュールがアップデートされた影響でプログラムが初期状態では正しく機能しないことが判明しております。
臨時の対応ですが、現在はコードを一文補ってやることで正常に動作します。
アップデート対応が確認出来次第、記事を更新し報告します。
Piano Transcriptionは「ピアノ曲のオーディオデータをMIDIにするソフト」
Piano Transcriptionはピアノ曲のオーディオデータを解析させるとMIDIデータに変換してくれるソフトです。
この時点で意味がわかる人にはこのソフトがどれだけ画期的なのかがわかります。
チート級です。異世界転生主人公です。
開発はTiktokでお馴染みのByteDanceです。
この動画は下の英語部分を読んで意味がわからないと何を伝えたいのかわかりにくいです。
解説すると、実際は録音した演奏と「録音のオーディオデータを基に生成したMIDIデータを再生したもの」を交互に動画に当てています。
ほぼそんなのわからないくらいに正確です。
よく聴くとところどころタイミングのズレを感じたりもしますがかなりの精度です。
利用はなんと無料です。
有料の耳コピ支援ソフトでもここまでしてくれないのに太っ腹過ぎる。
利用環境がやや曲者で、方法が2つあります。
- PCにPython, PyTorchの環境構築をした後にPiano Transcription本体とffmpegをインストールし、ターミナルでコマンド入力して使う
- Google Colab上で使う
私のM1 Mac miniではPythonがうまく機能しなかったのでこの記事ではGoogle Colabを利用する方法で解説します。
オンライン環境が必須になりますが、PC上に何もインストールしないまま使えるので不審なソフトウェアのインストールを警戒する必要もなく安心です。
使い方解説
手順概要
- Piano Transcription が使えるGoogle Colab Notebookを開く
- 解析させたいピアノのオーディオデータをアップロード
- Notebook内のコードを解析対象のデータに合わせて編集
- Notebook内のコマンドを順次実行
- 生成されたMIDIデータを確認
- 完了!
1.Piano Transcription が使えるGoogle Colab Notebookを開く
公式のGitHubページに移動します。
: https://github.com/qiuqiangkong/piano_transcription_inference
“Usage”の項目にあるGoogle ColabのリンクからNotebookを開きます。
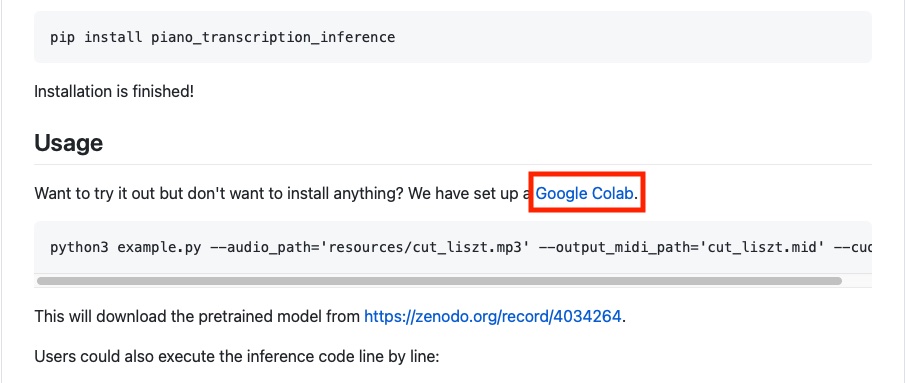
2. 解析させたいピアノのオーディオデータをアップロード
Google Colab Notebookの右メニューからフォルダ “content”を見つけます。
耳コピしてほしいオーディオデータをアップロードします。
“content”の中に耳コピしてほしいオーディオデータを入れます。
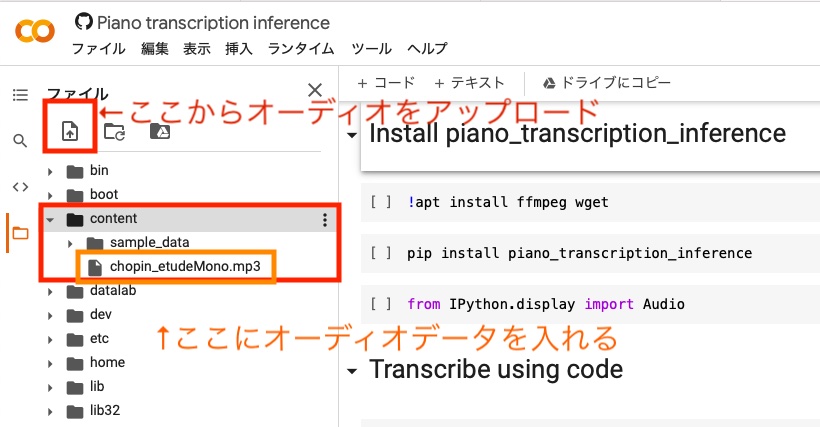
3.Notebook内のコードを解析対象のデータに合わせて編集
ここだけ少し難しいです。
文字の打ち間違いなど無いよう、慎重にいきましょう。
初期状態ではサンプルテストデータのリストの曲に設定されています。
その名称部分 “cut_liszt” の箇所を耳コピしてほしいオーディオファイルの名前に書き換えます。
打ち間違いがあると正常に実行されないので大文字小文字など要確認です。
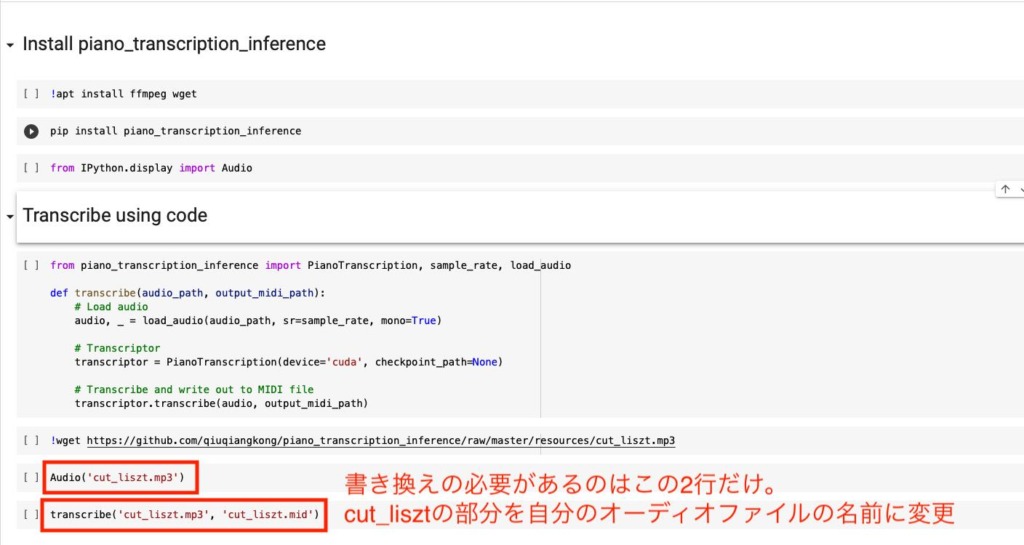
3.5.「pip install librosa==0.9.2」をコード2行目に追加 ※臨時対応部分
2023年3月のlibrosaアップデートにより、現在提供されているコード文では正常に機能しなくなってしまいました。
そのため、piano transcriptionのアップデートまでこちらの手順が必要になります。
画像のように
pip install librosa==0.9.2
をコードの2行目に追加しておきます。
これによりデフォルト状態のlibrosaより新しいバージョンのlibrosaをこのプログラム上で使うことができるようになり、この後のエラー発生を防ぐことができます。
4.Notebook内のコマンドを順次実行
ここまでくれば後は楽勝です。
Colab Notebook内のコードを上から順次クリックして実行していくだけです。
※この時3.5.で追加したコードも実行します。
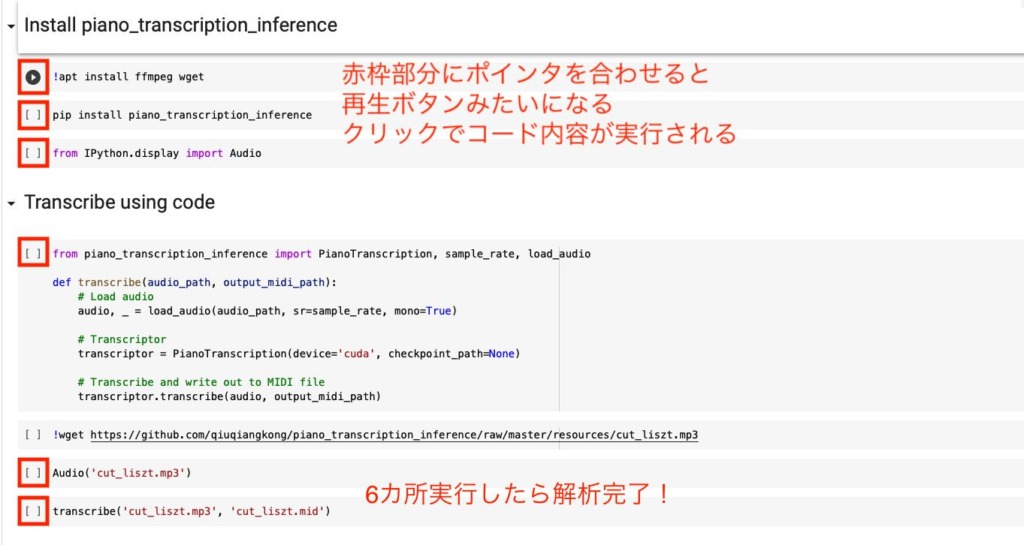
1カ所抜けてるように見えますが、そこは「テスト用のリストの曲のダウンロードを実行するコード」なので今回は使いません。
ちなみに間違って実行してしまっても特に問題ないので安心してください。
5.生成されたMIDIデータを確認
解析が正常に終了すると”content”フォルダ内に曲のMIDIデータが入っています。
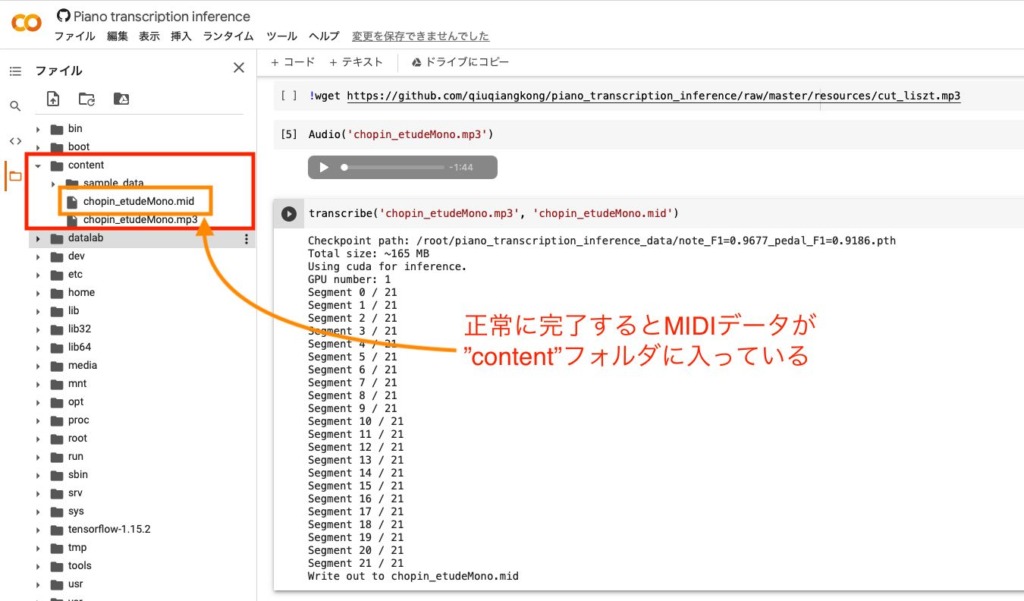
右クリックでダウンロードできるので自分のPCにダウンロードして終了です。
お疲れ様です。
検証実験 : 試しに超難しい曲を耳コピしてもらった

今回Piano Transcriptionの実力を試すにあたり、人間が耳コピするとしたらうんざりしそうなくらい難しい曲を選択しました。
著作権切れでないと使えないのでクラシック曲。念の為JASRACのページで確認済。
ショパンの12の練習曲より第4番 嬰ハ短調です。
数多あるクラシックピアノの曲でも難易度は10の指に入る超難曲。
速い、音数多い、臨時記号盛りだくさん。
普通に耳コピすることになったらうんざりするどころか発狂しそうです。
引用元 : IMSLP
解析によって生成されたMIDIデータをLogic上でピアノ音源を立ち上げ、再生したものがこちらです。
ピアニストの息遣いや収録したホールのリバーブまでは当然ながら再現されていません。MIDIなので。
ざっくり聴いた感じ、再現性はやはり高そうです。
検証用に難しい曲を選んだのは良かったのですが、難しすぎて私には細部の確認ができなくなってしまいました。
ここまで複雑な曲でもいい感じに耳コピしてくれるので、常識的な難易度の曲であればまず問題ないと感じます。
まとめ : ピアノ限定ではあるが耳コピの精度は抜群。
今回の記事ではByteDance「Piano Transcription」の紹介と使い方解説、性能評価を行いました。
まとめとしては
- ピアノ演奏のオーディオデータ(mp3でモノラル)をMIDIに変換してくれる
- 完全無料
- Google Colab経由で使えばソフトウェアのダウンロード不要で安心できる
- 超難曲もかなり高精度にMIDIで再現してくれる
といった感じでした。
無料ですが完全有料級のパワーです。
オーディオをMIDIに変換してくれるのでいろんな使い方ができます。
応用として例えば
- 楽譜が無い曲(あったとしても入手困難な曲)のピッチとリズムを把握する
- ノーテーションソフト(浄書ソフト)を用いてMIDIデータから楽譜を作成する
- ピアノ曲の耳コピを自力でした後に、答え合わせ用として活用する(MIDIデータなら視覚的に比較できる)
- ピアノループ素材の演奏のコードなどを把握する
といったことが思いつきます。
今回の記事は以上です。
お役に立てれば幸いです。
関連情報
使用したピアノ音源(ソフトウェア)について
今回のMIDIデータの再生にはXLN Audioの「Addictive Keys Studio Grand」を使いました。
静謐なピアノの落ち着きみたいな感じはありませんが、華やかではっきりした存在感を持つ音源です。
ポップスやロックといったジャンルの制作をされる方におすすめです。

ノーテーションソフト(楽譜作成ソフト)について
MIDIデータを使って楽譜を作るソフトウェアはいくつかあります。
個人的には「Dorico」がおすすめで私も使っています。
長く本格的に使うことを考えるなら「Finale」一択なのですが、5万円超と高額です。
しかもライトバージョンはMacに対応してません。(フルバージョンは対応済)
Doricoはライト版のDorico Elementsがあり、サウンドハウスならちょうど税込1万円で買えます。
体験版も公式にあるので一度試して見るのもありです。








コメント
コメント一覧 (24件)
初めまして、こんばんは。
とても有用な情報をありがとうございます。
記事の手順通りに行ったのですが、エラーが出てしまうので
もし解決法をご存じでしたら教えていただけないでしょうか> <?
記事内の手順で
【4.Notebook内のコマンドを順次実行】
まで行ったところ
6か所目の最後の再生ボタンを実行すると
AttributeError: No librosa.core attribute audio
というようなエラーが出てしまいうまくいかないのです><
こちらはその時のスクショです
https://imgur.com/9vtwlpe
もし解決方法をご存じでしたら教えていただけないでしょうか?
よろしくお願いいたしますm(_ _)m
コメントありがとうございます。
いただいたご指摘を私の方でも検証しましたところ、同様のエラーが発生しました。
原因を調査した結果、Piano Transcriptionのプログラム内で音声処理を担う「librosa」というプログラムが最近アップデートされた影響で、現状のコードでは正しく機能しなくなってしまったようです。
それではいつ更新されるのか?についてはプログラム制作者次第になってしまいます。
希望的観測ですが現在Github内で既に同じ問題が提起、改善要望提出されているので、そう遠くないうちに更新対応は期待できます。
ご不便をおかけして申し訳ありません。
同様の問題を避けるべく、記事中に現在は正常に利用できない旨の注意書きを追記いたします。
さっそくのお返事ありがとうございます
アップデートに伴う不具合とのことで、自分側の問題ではなくひとまず良かったです
制作者様の更新対応を待ちたいと思います
ありがとうございましたm(_ _)m!
自分もエラー出てましたが
https://github.com/qiuqiangkong/piano_transcription_inference/issues/16
↑にある通り、
pip install librosa==0.9.2 #ここ追加
pip install piano_transcription_inference
して再起動すればできました!
意外と精度があってびっくりしました
コメントと情報提供ありがとうございます!
この方法を私の方でも検証し、適切に動作することが確認されました!
問題発生から3週間程度経過した現在も製作者による修正がなされないので、ひと手間増えますが、しばらくはこの方法で使うのが賢明かもしれません。
エラーがaudio load の部分に出ます。これは( )が必要ですか?
File “”, line 4
audio._ = load_audio(audio_path, sr=sample_rate, mono=True)
(audio._)を付けてもエラーです。
文法がちがうのでしょうか?
お手数ですが、この部分がわかりません。
5月4日時点、私の方で動作確認したところ、記事の方法で正常動作しました。
おくさんがオリジナルのオーディオデータを解析させようとしている場合、
・変更必須箇所の記述が不正確(ファイル名が一致していないなど)
・オーディオデータがモノラル形式でない
のどちらかが原因だと思われます。
私はPythonの専門家ではないので細かい文法の正否はわかりません。
初めまして、こんばんは。
試してみたところ、NvidiaのGPUを使用していないエラーが出るようですね。
(CUDAが使用できること)
# Transcriptor
transcriptor = PianoTranscription(device=’cuda’, checkpoint_path=None)
該当箇所のcudaをcpuに書き換えたらうまくいきました。
以上ご報告まで。
初めまして!コメントありがとうございます!
5/4時点で検証したところ、私の環境では記事の方法で正常動作しました。
気になって調べたところ、Google Colabの使用状況によってはGPUリソースが制限されることがあるようです。
それにより一時的にCUDAが使用できない場合に引っかってしまったのかもしれません。
リソース制限下では、ご教示いただいた「GPUをCPUに置き換えて動作させる手法」は効果的ですね!
ご報告ありがとうございます。
最終的にローカルで成功しました!
colaboよりrootフォルダにあるnote_F1=0.9677_pedal_F1=0.9186.pthをDLしたところ、うまく動作しました。ご報告まで。
初めまして、とても便利な情報を提供いただきありがとうございます。
下記内容を試してたのですが
・pip install librosa==0.9.2の追加
・transcriptor = PianoTranscription(device=’cuda’, checkpoint_path=None)
該当箇所のcudaをcpuに書き換え
・colaboよりrootフォルダにある・・(見当たらない)
下記のような表示になりMIDIに変換できませんでした。
https://imgur.com/DVcHcEk
(pip install librosa==0.9.2の追加を試した際の結果)
解決方法があればご教示いただければ幸いです。
宜しくお願い致します。
お役に立てて嬉しく思います。
頂いた画面情報のエラーメッセージを見たところ、
AttributeError: No librosa.core attribute audio
とあることから、librosaが正しくインストールされていないことが原因と思われます。
>・pip install librosa==0.9.2の追加
こちらの文章からlibrosa 0.9.2をインストールするコードは追加いただいていると見受けられます。
考えられる原因としては
1.追加コード「pip install librosa==0.9.2」を適切な位置に入れることができていない
2.「pip install librosa==0.9.2」が無い状態で一度「pip install piano_transcription_inference」を実行してしまっており、古いバージョンのlibrosaをセッションにインストールしてしまった
上記2点のいずれか、もしくは両方かと思われます。
1の場合はコード追加箇所を改めてご確認いただきたく存じます。
具体的には「!apt install ffmpeg wget」と「pip install piano_transcription_inference」の間に「+ コード(コードセルを追加)」で入れる必要があります。
2.の場合はGoogle Colabの画面で失敗したセッションを終了させ、新たにセッションを立ち上げ直す必要があります。
画面左上メニューの「ランタイム」→「セッションの管理」→「アクティブなセッション」と進み、該当セッションの右に表示されたゴミ箱マークから、セッションを終了させてください。
その後新たにPiano transcription inferenceのセッションを作成し、「pip install librosa==0.9.2」を追加してから実行してみてください。
こんばんは。
最後のTranscribeの項目でAttributeError: No librosa.core attribute audioとエラーが発生します。
pip install librosa==0.9.2は実行しているのですが、こちら原因わかりまうでしょうか…?
こんばんは。
同様のエラー対処法を別のコメントで回答いたしました。
そちらをご覧ください。
返信ありがとうございます!
2行目を書き換えてしまっていたためコードを追加する形で解決致しました!非常に助かりました。ありがとございます!
大変有益なソフトを紹介して頂いてありがとうございます。1つ質問なのですが、現時点で複雑なピアノ演奏のオーディオファイルを高精度でmidi変換できるソフトは、これ以外に存在するのでしょうか?有料無料問わず把握されている範囲で構わないので教えて頂けると幸いです。
お役に立てて幸いです。
ご質問の回答ですが、「複雑なピアノ演奏のオーディオファイルを高精度でmidi変換できるソフト」は私の知る限りpiano transcriptionの他にありません。
一方でpiano transcriptionも公表されてから3年くらいになるので、まだ一般公開されていない範囲ではより高性能なものが存在する可能性は高いと考えています。
はじめまして。とても面白いサイトをありがとうございます。
下から2つ目の箇所でエラーが起こってしまいます。
Audio(‘wheelswithinwheels.mp3’)
—————————————————————————
ValueError Traceback (most recent call last)
in ()
—-> 1 Audio(‘wheelswithinwheels.mp3’)
/usr/local/lib/python3.10/dist-packages/IPython/lib/display.py in __init__(self, data, filename, url, embed, rate, autoplay, normalize, element_id)
114 if self.data is not None and not isinstance(self.data, bytes):
115 if rate is None:
–> 116 raise ValueError(“rate must be specified when data is a numpy array or list of audio samples.”)
117 self.data = Audio._make_wav(data, rate, normalize)
118
ValueError: rate must be specified when data is a numpy array or list of audio samples.
ValueErrorなのでMP3の音源がおかしいのかと思いましたが、MP3に特に問題はないようです。
対処法等ご存じでしたらご教示いただけますと幸いです。
お褒めの言葉ありがとうございます。
いただいたエラーメッセージを拝読したところ、
”解析対象であるmp3データのサンプルレートがPiano Transcription非対応のもの(指定されていないもの)であること”
に起因するエラーと見受けられます。
Piano Transcriptionの対応サンプルレートは、専門家でない私には明確に分かりませんが、
2023年11月4日時点で軽く検証したところ、以下のサンプルレートのmp3データは正常に解析されたことを確認しました。
32kHz, 48kHz
nekoさんが解析させたいmp3データのサンプルレートの値を一度確認し、上記サンプルレートでなかった場合はDAWなどで上記サンプルレートに変換して再び試してみてください。
ご返信ありがとうございます。
確認してみます!
表示はされていませんが何週間か前に、コメントを送信させていただいた者です。その時、「pip install librosa==0.9.2」を追加しなくてもmidiが生成できました、ということを書かせていただいたのですが(実際なぜかうまくいったので)、本日再度やってみたところ、やはり「pip install librosa==0.9.2
」を追加しないとエラーになりましたが、追加するとちゃんとmidiができました。本当に助かります!有益な情報をありがとうございました。また、前回送信したコメントにつきまして、もし検証いただくなどご迷惑をおかけしていたら申し訳ございませんでした。
コメントありがとうございます。
「何週間か前にコメントを送信された」とのことですが、それらしいものが見つからなかったので、検証など対応をしておりませんでした。
そのためお気になさらなくて大丈夫です。
本記事がお役に立てたのなら幸いです。
> Piano Transcriptionの対応サンプルレートは、専門家でない私には明確に分かりませんが、
2023年11月4日時点で軽く検証したところ、以下のサンプルレートのmp3データは正常に解析されたことを確認しました。
32kHz, 48kHz
変換できたビットレートってわかります?
Audio:MPEG Audio Layer 3 32000Hz mono 64Kbps
32kHzではあるのですが、nekoさんと同じ状態です
先週コメントした者ですが、解消したのでお知らせしておきます
ビットレートは40kbpsでできました